

前言
现在平台上的漫画大多都压缩的很糊,手机端看起来还可以,平板就真的看不下去,网上提升画质的模型很多,但是没有专们搞漫画的工具,我就自己做了一个 现在这个还有很多不足,欢迎提意见改正 ,如果有帮助的话我会很开心
效果可以去移动云盘看看 现在搞了金牌的主的到58话 漫画
使用教程
下载启动
导入素材
第一页是导入素材的地方,可以在网上下好素材 ,我推荐贴吧,或者直接在拷贝下载 ,我大多都在拷贝上看的,推荐一下拷贝漫画下载器 GitHub 拷贝漫画下载器
要是没有梯子的话可以直接 在夸克里一块下了
功能模块
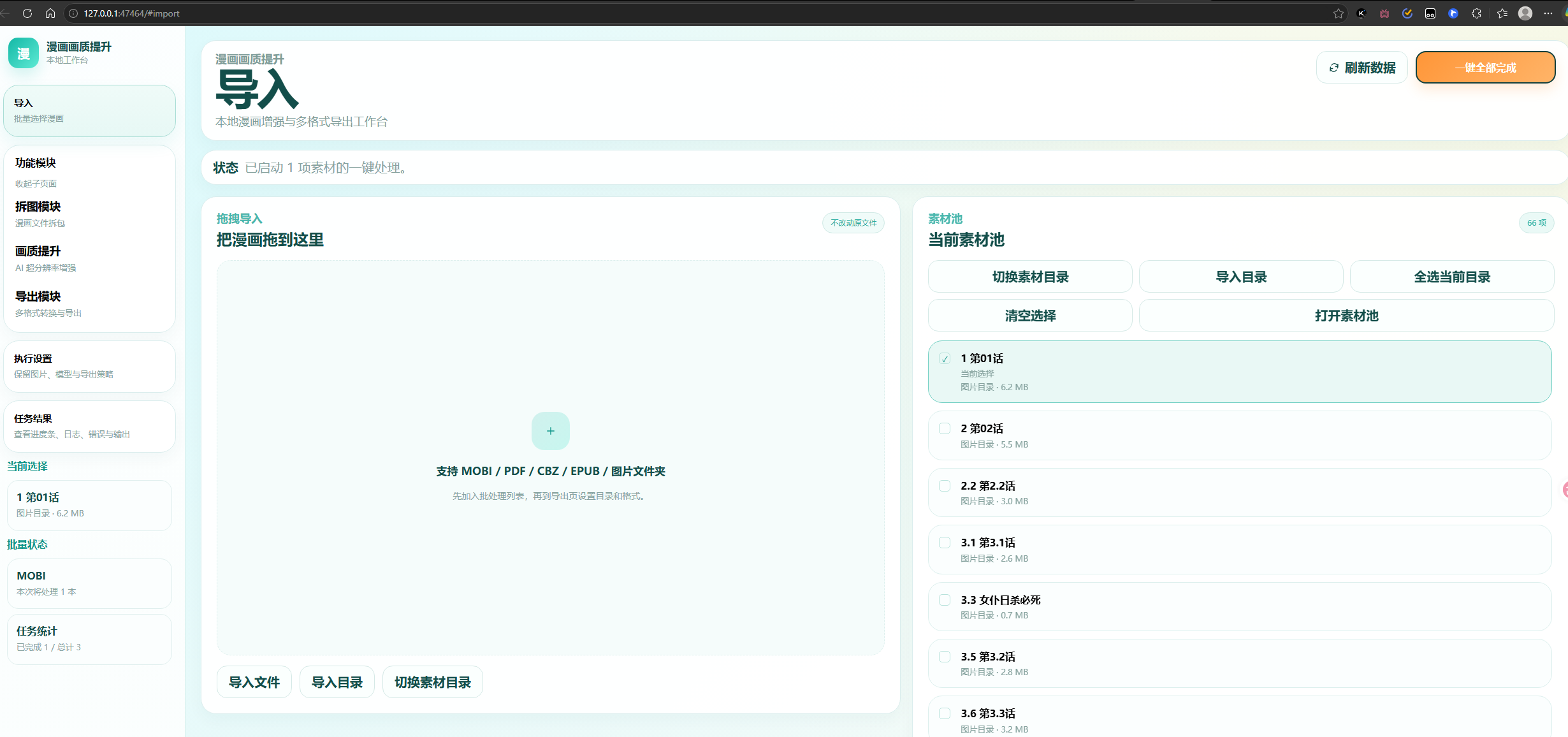
然后是功能模块 漫画要拆成图片才能让模型提升画质 ,第一个就是拆页了,拆完后不用我的模型自己搞一个也行
第二个是画质增强 我想其他图片之类的也能用我这个来提升画质 ,但预览页一直没太搞好
带三个是导出模块 就是图片导出成漫画格式 ,好像还有几种没加上,推荐cbz或者zip 其他格式或许有点小bug 之后会修,有时间在加几个格式
执行模块
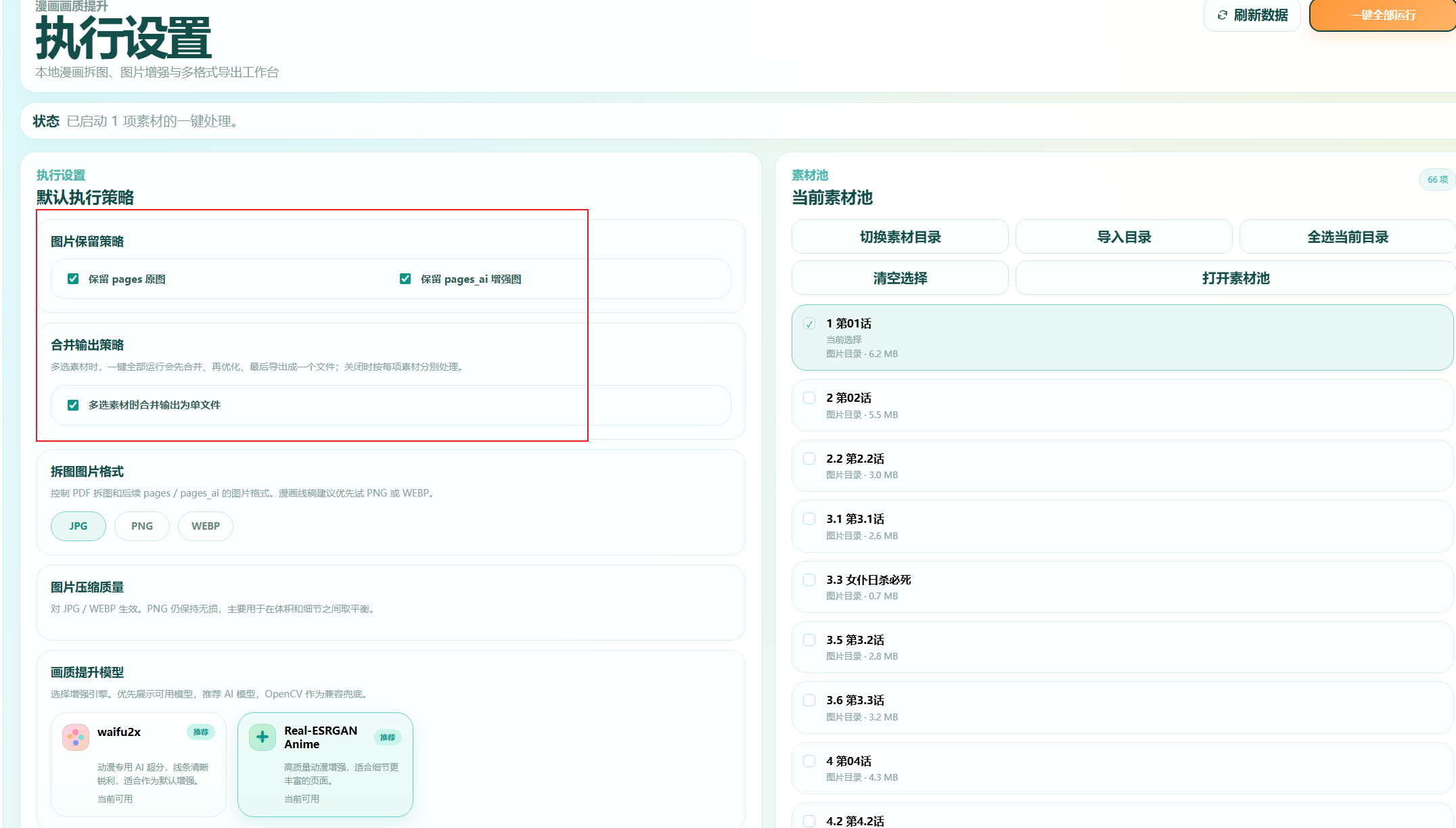
最后是执行模块 要是就像提升画质就看这个就行了,我搞了是否保留原本图片和画质增强的图片,这个可以自己选 合并成一个文件,这个还是蛮有用的不然一大堆还是挺麻烦的
任务列表
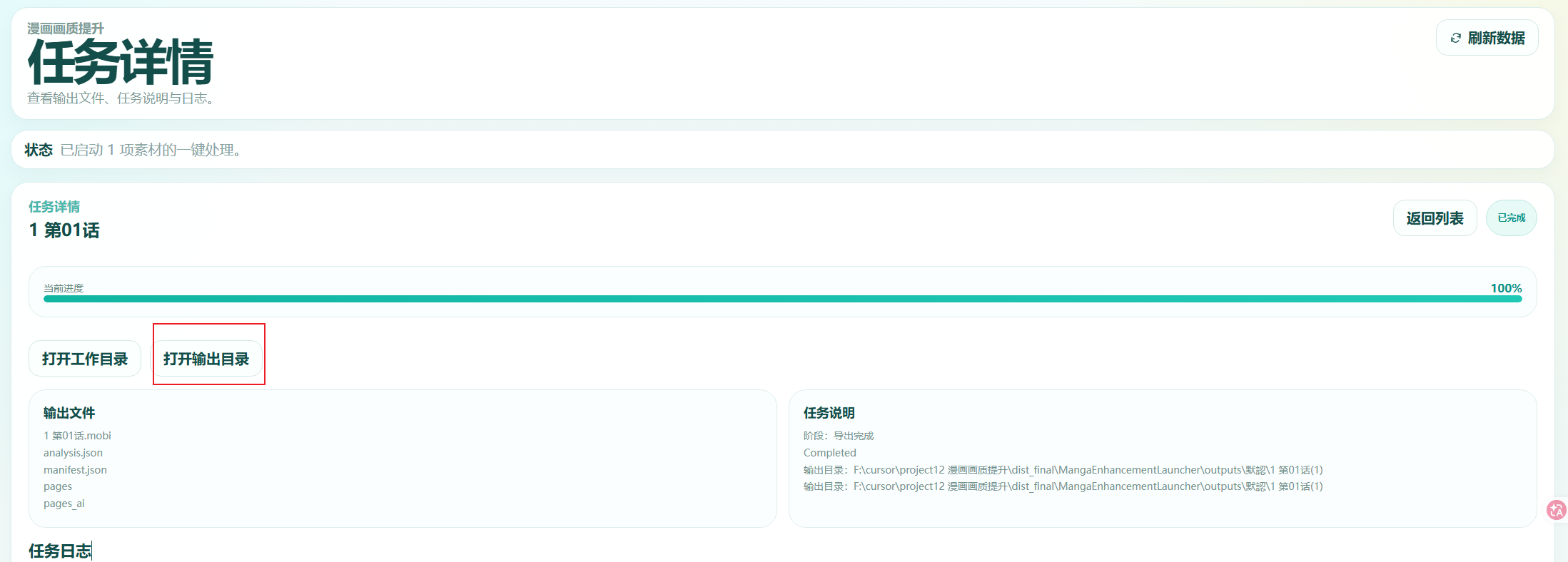
然后就是任务列表了 在任务列表里看进度 ,点进去按打开输出目录就可以很方便跳转到文件夹位置
分析一下该项目 写博客
技术说明
一、项目概述
MOBI Manga Enhancer 是一个面向 Kindle 漫画阅读场景的本地画质增强工具。它能够将低分辨率的 MOBI、CBZ、PDF 等格式的漫画资源,通过 AI 超分辨率模型与传统图像处理算法的协同工作,输出高清晰度的 CBZ 文件,并可直接对接 Kindle Comic Converter (KCC) 转换为 Kindle 设备可读格式。
整个项目完全本地离线运行,不上传任何数据,确保隐私安全。
技术栈一览:
| 层级 | 技术选型 |
|------|----------|
| 后端 | Python 3.12+ |
| 图像处理 | OpenCV、Pillow、PyMuPDF (fitz) |
| AI 超分辨率 | Real-ESRGAN (PyTorch)、Waifu2x-NCNN-Vulkan |
| GUI 启动器 | PySide6 |
| 前端 | React 18 + Vite 5 |
| API | 原生 http.server.ThreadingHTTPServer |
| 打包分发 | PyInstaller + Inno Setup |
二、系统架构
项目采用经典的前后端分离架构,后端 Python 通过 HTTP API (端口 8765) 为 React 前端提供 RESTful 服务,同时提供 CLI 命令行入口,满足不同使用场景。
┌─────────────────────────────────────────────────────────────┐
│ 用户交互层 │
│ ┌──────────────┐ ┌──────────────────┐ ┌──────────────┐ │
│ │ React 前端 │ │ PySide6 启动器 │ │ CLI 命令行 │ │
│ │ (Web 界面) │ │ (桌面 GUI) │ │ (脚本化) │ │
│ └──────┬───────┘ └──────┬───────────┘ └──────┬───────┘ │
└─────────┼─────────────────┼──────────────────────┼──────────┘
│ │ │
▼ ▼ ▼
┌─────────────────────────────────────────────────────────────┐
│ HTTP API 层 (api.py) │
│ ThreadingHTTPServer :8765 │
├─────────────────────────────────────────────────────────────┤
│ 工作流层 (workflow.py) │
│ ┌────────┐ ┌────────┐ ┌─────────┐ ┌────────┐ ┌────────┐ │
│ │ Import │ │ Analyze│ │ Enhance │ │Package │ │ Export │ │
│ └────┬───┘ └───┬────┘ └────┬────┘ └───┬────┘ └───┬────┘ │
├───────┼─────────┼──────────┼──────────┼──────────┼─────────┤
│ ▼ ▼ ▼ ▼ ▼ │
│ ┌─────────┐ ┌────────┐ ┌────────────────────────────┐ │
│ │ unpack │ │analyze │ │ Enhancer Registry │ │
│ │ .py │ │ .py │ │ ┌─────────┐ ┌──────────┐ │ │
│ │ │ │ │ │ │Real-ESRGAN│ │ Waifu2x │ │ │
│ │ MOBI │ │ Page │ │ │ Anime │ │ NCNN │ │ │
│ │ CBZ/ZIP │ │Profile │ │ │ (PyTorch)│ │ (Vulkan) │ │ │
│ │ PDF │ │Quality │ │ ├─────────┤ ├──────────┤ │ │
│ │ Folder │ │ Score │ │ │Real-ESRGAN│ │ OpenCV │ │ │
│ └─────────┘ └────────┘ │ │ General │ │ (内置) │ │ │
│ │ └─────────┘ └──────────┘ │ │
│ └────────────────────────────┘ │
├─────────────────────────────────────────────────────────────┤
│ 基础设施层 │
│ ┌──────────┐ ┌───────────┐ ┌────────────────┐ │
│ │ JobStore │ │RuntimePaths│ │ External Tools │ │
│ │ (持久化) │ │ (路径解析) │ │KindleUnpack/KCC│ │
│ └──────────┘ └───────────┘ └────────────────┘ │
└─────────────────────────────────────────────────────────────┘2.1 核心模块职责
| 模块 | 文件 | 职责 |
|------|------|------|
| 流水线编排 | pipeline.py | 一键式端到端处理:解包→分析→增强→打包 |
| 工作流引擎 | workflow.py | 分步式精细控制:Import/Analyze/Enhance/Optimize/Package/Export |
| 页面分析 | analyze.py | 多维度质量评分与页面类型分类 |
| 智能增强 | enhance.py | 多策略降级、AI 预处理、质量验证 |
| 源文件解包 | unpack.py | MOBI/CBZ/PDF/Folder 多格式解包与归一化 |
| 导出打包 | repack.py | CBZ/PDF/ZIP 封装,KCC 集成 |
| 增强引擎 | enhancers/ | 插件式 AI 引擎注册与管理 |
| API 服务 | api.py | HTTP RESTful API,支持前端 Dashboard |
| 任务持久化 | job_store.py | Job 状态管理,支持断点恢复 |
| 运行时路径 | runtime_paths.py | 开发/打包/便携三模式路径自适应 |
三、处理流水线详解
整个流水线设计为 六阶段有向无环流,每个阶段可独立运行,也可组合为完整流水线:
3.1 阶段一:Import(源文件解包)
输入: .mobi / .cbz / .zip / .pdf / 图片文件夹
│
├─ MOBI/AZW3 → KindleUnpack 提取 → XHTML 解析 <img> 标签 → 收集图片
│ ↓ 回退
│ Images 目录扫描
├─ CBZ/ZIP → zipfile 解压 → 扫描图片文件
├─ PDF → 逐页决策(见下文)→ 归一化命名 page_NNNN.ext
└─ Folder → 直接扫描
│
输出: pages/ 目录(统一命名、统一格式的原始页面图片)PDF 智能处理是此阶段的亮点。 对于 PDF 漫画,系统不是简单地全部渲染或全部提取,而是逐页决策:
# _decide_pdf_page_mode() 的决策逻辑
if mode == "extract":
source_mode = "extract" # 强制提取
elif mode == "render":
source_mode = "render" # 强制渲染
elif picked is None:
source_mode = "render" # 无内嵌图片 → 渲染
elif quality_mode == "fast_auto":
source_mode = "extract" # 快速模式优先提取
elif has_vector_content:
source_mode = "render" # 矢量内容 → 渲染
elif embedded_size < target_size * 0.85:
source_mode = "render" # 内嵌图太小 → 渲染
else:
source_mode = "extract" # 内嵌图足够大 → 直接提取决策结果会写入 pdf_split_meta.json,供后续增强阶段作为上下文参考。每个页面还会检测是否存在矢量内容(文字/绘图),这对增强时的参数选择至关重要。
3.2 阶段二:Analyze(页面质量分析)
系统对每一页提取 8 项图像质量指标,并据此进行页面类型分类:
| 指标 | 算法 | 含义 |
|------|------|------|
| Sharpness | Laplacian 方差 | 图像整体锐度 |
| Edge Density | Canny 边缘检测 | 线条/轮廓密度 |
| Blockiness | 8px 边界像素差均值 | JPEG 压缩块效应 |
| Text Density | OTSU 二值化 + 连通域分析 | 文字占比 |
| Line Density | Canny 边缘占比 | 线稿密度 |
| Halftone Score | Laplacian 能量 + 局部残差 | 半色调/网点特征 |
| Noise Score | 中值滤波残差均值 | 噪声水平 |
| Background Cleanliness | 高亮区域均值/标准差 | 背景纯净度 |
基于这些指标,系统通过决策树将页面分为 5 种画像 (Profile):
def _classify_page_profile(...):
if is_color: return "color_illustration"
if noise >= 0.42 or blockiness >= 14 or cleanliness < 0.18:
return "low_quality_scan"
if text_density >= 0.22: return "text_heavy"
if halftone >= 0.34: return "halftone_gray"
# 默认: return "lineart_bw"同时计算一个综合质量分数 (0~100),基于锐度加分、分辨率加分、块效应/噪声减分。
3.3 阶段三:Enhance(智能增强)——核心算法
这是整个系统最具技术含量的部分,包含三个关键设计:
3.3.1 基于页面画像的策略路由
系统根据每页的 page_profile 和处理策略 (strategy),动态构建不同的增强尝试序列。以默认的 quality_auto 策略为例:
| 页面画像 | 第一选择 | 第二选择 (降级) | 第三选择 (兜底) |
|----------|----------|-----------------|-----------------|
| color_illustration | Real-ESRGAN Anime (standard) | Waifu2x (standard) | — |
| lineart_bw | Waifu2x (standard, noise=1) | Waifu2x (conservative) | Real-ESRGAN Anime (conservative) |
| text_heavy | Waifu2x (conservative, noise=0) | Waifu2x (conservative, noise=-1) | Real-ESRGAN Anime (conservative) |
| halftone_gray | Waifu2x (conservative, noise=0) | Waifu2x (conservative, noise=-1) | Real-ESRGAN Anime (conservative) |
| low_quality_scan | Waifu2x (conservative, noise=2) | Waifu2x (conservative, noise=1) | Real-ESRGAN Anime (conservative) |
设计考量: 线稿和文字页首选 Waifu2x,因其对线条的保持能力优于 Real-ESRGAN;低质量扫描页开启去噪 (noise=2);半色调和文字页关闭去噪 (noise=0/-1),避免破坏网点纹理;彩色插画页优先使用 Real-ESRGAN Anime 以获得更好的色彩还原能力。
对于检测到矢量内容的 PDF 页面,系统会自动将所有尝试降级为 conservative 模式并禁用去噪,防止 AI 引擎在矢量转栅格的页面上产生过度增强伪影。
3.3.2 AI 预处理流水线
图像在送入 AI 模型之前,经过一个精心设计的 LAB 色彩空间预处理:
def _preprocess_for_ai(image, options, page_metrics):
# 1. 转换到 LAB 色彩空间,分离亮度与色度
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
l_channel, a_channel, b_channel = cv2.split(lab)
# 2. 亮度通道归一化(拉伸到 0-255 全动态范围)
l_channel = cv2.normalize(l_channel, None, 0, 255, cv2.NORM_MINMAX)
# 3. 非局部均值去噪(仅作用于亮度通道,保留色度不变)
l_channel = cv2.fastNlMeansDenoising(l_channel, None, h=4 + max(noise, 0))
# 4. 低质量扫描特殊处理:附加中值滤波去除块效应
if pdf_source == "extract" and (low_quality or blockiness >= 10):
l_channel = cv2.medianBlur(l_channel, 3)
# 5. 亮度补偿:防止偏暗页面增强后进一步变暗
bright = np.percentile(l_channel, 97)
if bright > 0:
scale = min(255.0 / bright, 1.08) # 最大补偿 8%
l_channel = clip(l_channel * scale, 0, 255)
# 6. 合并回 BGR
return cv2.cvtColor(merge(l, a, b), cv2.COLOR_LAB2BGR)预处理后经 AI 模型增强,再施加一个双边滤波 (bilateralFilter d=5, σ_color=12, σ_space=12) 作为后处理,在保持边缘的同时平滑 AI 模型可能引入的噪声。
3.3.3 增强结果质量验证
每次增强尝试后,系统不会盲目接受结果,而是执行严格的验证检查:
def _validate_candidate(original, candidate, page_profile, page_metrics, enhancer):
# 1. 亮度检查:防止过暗/过曝
if candidate_mean < original_mean * 0.72: → "output too dark"
if candidate_mean > original_mean * 1.28 + 12: → "output overexposed"
# 2. 边缘保持检查:防止线条退化
if lineart/text and candidate_edges < original * 0.79: → "edge clarity regressed"
# 3. 锐度检查:防止过度锐化
if candidate_sharpness > original * 5.5 + 4000: → "oversharpened"
# 4. 块效应检查:防止引入压缩伪影
if halftone and candidate_blockiness > original * 1.35 + 1.5: → "halftone artifacts increased"
# 5. PDF 特殊检查
if pdf_render and edges_drop_significant: → "pdf render edge clarity regressed"
if pdf_vector and sharpness_spike: → "pdf vector page oversharpened"验证不通过则自动降级到下一个增强策略。如果所有策略都失败,则将原图直通 (passthrough) 保存,保证输出完整性。
3.4 阶段四至六:Optimize → Package → Export
-
Optimize:将增强结果复制到输出目录的
pages_ai/子目录 -
Package:将页面打包为目标格式(CBZ/PDF/ZIP),MOBI/EPUB 通过调用 KCC 生成
-
Export:写入
manifest.json清单文件,可选清理中间文件
四、增强引擎插件体系
系统采用注册器模式 (Registry Pattern) 实现增强引擎的插件化管理:
4.1 基类设计
class BaseEnhancer(ABC):
@abstractmethod
def name(self) -> str: ... # 引擎唯一标识
@abstractmethod
def requires_gpu(self) -> bool: ... # GPU 依赖声明
@abstractmethod
def is_available(self) -> bool: ... # 运行时可用性检查
@abstractmethod
def enhance(self, image, options) -> np.ndarray: ... # 核心增强方法基类还提供了 enhance_file() 默认实现,统一处理灰度图→BGR 3通道的转换、BGRA 透明通道剥离、GIF 帧提取等边界情况,子类只需关注增强算法本身。
4.2 引擎注册与自动发现
_AUTO_PRIORITY = ["realesrgan-anime", "waifu2x"] # AI 引擎优先级
def _ensure_enhancers_loaded():
# 延迟导入,缺依赖的引擎静默跳过
try: from .realesrgan_anime_enhancer import RealESRGANAnimeEnhancer; register(...)
except: pass
try: from .waifu2x_enhancer import Waifu2xEnhancer; register(...)
except: pass
register(OpenCVEnhancer) # 内置引擎始终可用这种设计确保了:即使只安装了 OpenCV,系统仍可运行(降级到传统增强);安装了 AI 引擎时,自动按优先级选择最优方案。
4.3 各引擎技术细节
Real-ESRGAN Anime
-
模型:
realesr-animevideov3.pth(SRVGGNetCompact, 4x 上采样) -
推理后端: PyTorch,自动检测 CUDA 可用性,GPU 可用时启用 FP16 (
half=True) -
Tiling:
tile=512, tile_pad=10,控制显存占用 -
兼容性补丁: 针对 PyInstaller 打包环境,运行时修复
basicsr和realesrgan的包导入路径;针对新版 torchvision 移除functional_tensor模块的问题,动态注入兼容实现
Waifu2x-NCNN-Vulkan
-
模型:
models-cunet(默认,适合通用动漫) /models-upconv_7_anime_style_art_rgb -
推理后端: NCNN Vulkan,优先 GPU (
gpuid=0),失败回退 CPU -
参数控制: 支持 noise (-1~3)、scale、tta_mode、model 选择
-
尺寸校准: 模型输出尺寸可能与目标不一致,通过
INTER_LANCZOS4插值校正
OpenCV (内置降级方案)
纯传统图像处理流水线,无任何外部依赖:
非局部均值去噪 → LANCZOS4 上采样 → CLAHE 对比度增强 → 混合保留暗部 → USM 锐化通过 mode 参数控制三档强度:conservative / standard / strong,调整去噪强度、锐化幅度和对比度混合比。
五、运行时路径系统
项目需要同时支持开发环境、PyInstaller 打包版、便携版三种部署模式,路径解析的复杂性不容忽视。
runtime_paths.py 通过检测 sys.frozen 属性和文件系统特征,自动判断运行模式:
def get_runtime_paths():
frozen = bool(getattr(sys, "frozen", False))
if frozen:
# PyInstaller 打包模式:基于可执行文件所在目录
install_root = Path(sys.executable).parent
runtime_mode = "bundle"
else:
# 检测是否为 bundle 目录结构(有 frontend/tools/models 等子目录)
bundle_root = python_dir.parent if python_dir.name == "python" else None
if bundle_root and has_bundle_indicators(bundle_root):
install_root = bundle_root
runtime_mode = "bundle"
else:
# 开发模式:基于仓库根目录
install_root = repo_root
runtime_mode = "dev"RuntimePaths 类的每个属性都使用 _first_existing(*candidates) 模式,按优先级搜索多个候选路径,确保在所有部署模式下都能正确定位资源文件(模型、工具、前端构建产物等)。
六、任务管理与容错
6.1 JobStore 持久化
所有任务状态持久化到 JSON 文件,支持 API 重启后恢复:
-
任务创建时写入
appdata/jobs.json -
后台任务进度通过节流机制(0.75s 间隔)定期持久化
-
API 启动时自动恢复中断的任务(标记为
failed,提示用户)
6.2 后台任务架构
def _run_in_background(store, job, step):
def worker():
try:
# 执行对应阶段的 workflow
# 实时更新进度到 JobStore
except Exception:
# 捕获异常,标记任务失败,保留完整错误堆栈
threading.Thread(target=worker, daemon=True).start()所有耗时操作(增强、打包)都在守护线程中异步执行,API 立即返回 202 Accepted,前端通过轮询获取进度更新。
七、前端设计
React 前端作为 Web Dashboard 提供可视化操作界面:
-
源文件管理:拖拽上传、文件夹导入、文件预览
-
任务控制:分步执行 / 一键全流程、参数配置
-
实时预览:增强前后对比,基于 SHA1 的预览缓存机制
-
进度追踪:任务列表、阶段进度、日志输出
-
多源合并:选择多个源文件合并为单一输出
前端通过 Vite 构建,静态文件由 Python 后端的 http.server 直接托管,无需 Nginx 等独立 Web 服务器。
八、构建与分发
项目提供完整的 Windows 分发方案:
# 开发环境
pip install -e .
cd frontend && npm install && npm run dev
# 生产构建
cd frontend && npm run build
scripts/build-launcher.ps1 # PyInstaller 打包
scripts/build-release.ps1 # Inno Setup 安装包 + 便携版 ZIP分发产物:
| 格式 | 说明 |
|------|------|
| setup.exe | Inno Setup 安装包,含完整依赖 |
| portable.zip | 便携版,解压即用 |
| AI 模型 | 需单独下载放置到 models/ 目录 |
九、技术亮点总结
-
感知驱动的智能增强:不是”一刀切”的超分辨率,而是根据每页内容类型(线稿/文字/网点/彩页/扫描件)动态选择最优增强策略与参数组合
-
多级降级容错机制:每个增强策略都预设 2~3 级降级路径,配合严格的质量验证门控,确保在任何情况下都不会输出劣于原图的结果
-
PDF 逐页智能决策:区分矢量/光栅内容,根据内嵌图片分辨率自动选择提取或渲染模式,并记录决策元数据供下游使用
-
LAB 色彩空间预处理:分离亮度与色度处理,在去噪的同时保持色彩保真度,亮度补偿机制防止暗部丢失
-
插件式引擎架构:注册器模式 + 延迟导入,引擎可选安装,缺依赖时静默降级,保持系统鲁棒性
-
全链路离线运行:AI 推理完全本地化,不依赖任何云端 API,适合处理版权敏感的漫画资源
十、适用场景
-
Kindle 漫画读者需要提升低分辨率漫画画质
-
将 MOBI 格式漫画转换为 CBZ 格式并增强
-
批量处理 PDF/CBZ 漫画资源的画质优化
-
扫描版漫画的数字化增强与清晰化
部分信息可能已经过时